Course overview
1 Introduction
The goal of this course is to study the more advanced aspects of the implementation of programming languages.
We assume that students have already followed an introductory course on compilers, and in particular that they are familiar with what is commonly known as the front-end of compilers: parsing, name analysis and type checking. This course will not cover these subjects at all, and instead concentrate on the back-end of compilers for high-level functional and object-oriented languages, as well as run time systems.
2 Compilers
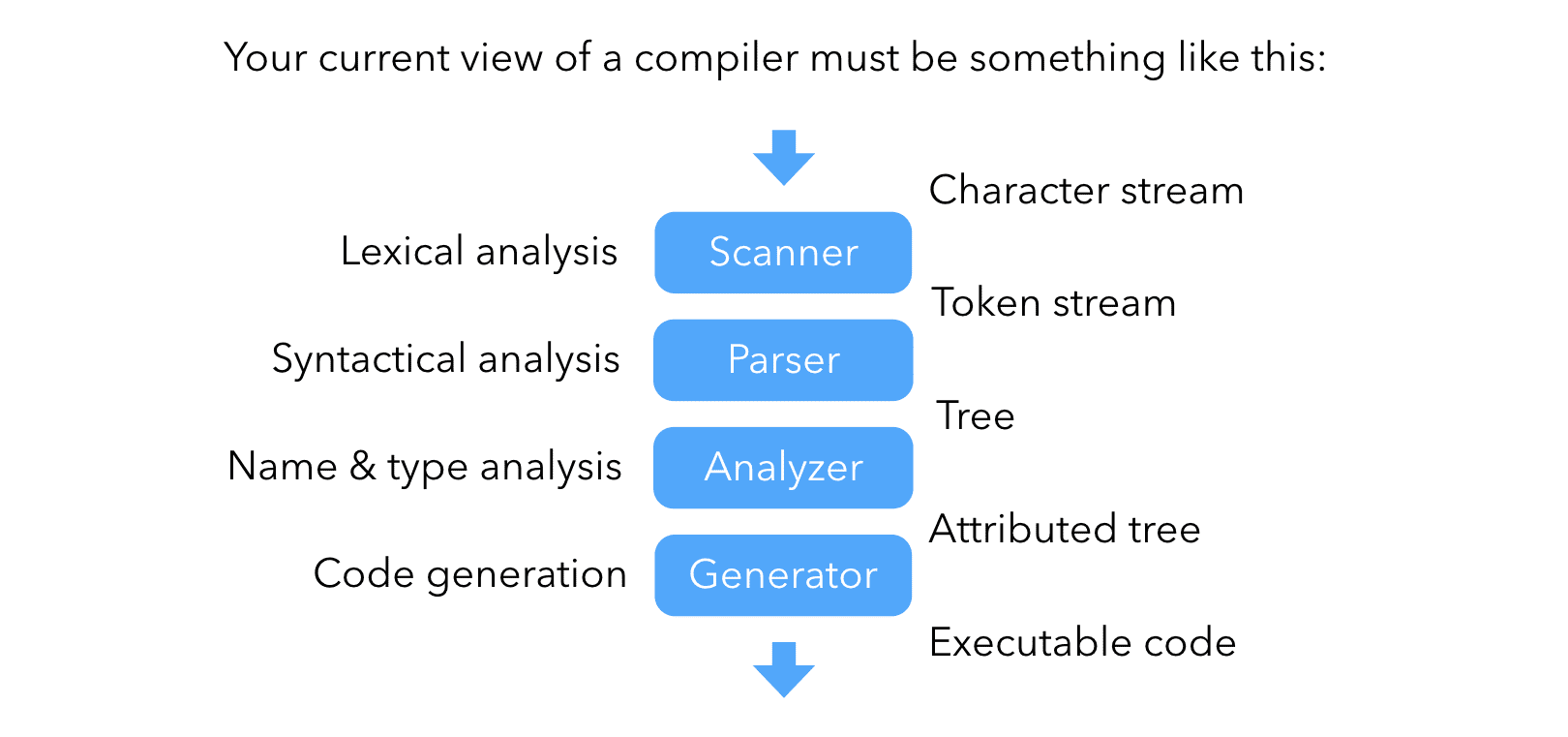
A simple compiler is typically composed of a set of front-end phases — a scanner, a parser, a name analyzer and maybe a type analyzer — that analyze the input program and make sure it is valid. These phases usually produce an abstract syntax tree of the program, which is then processed by a very simple back-end composed of a single code-generation phase producing the target program. This is illustrated by the picture below:
Realistic compilers tend to be more complicated, for two reasons: first, their back-end includes several simplification and optimization phases, and second the compiler is accompanied by a sophisticated run time system, as illustrated in the image below:

This course examines the implementation of these additional phases, and of several aspects of run time systems. A brief overview of these two subjects is given below.
3 Simplification and optimization phases
The additional phases that non-trivial compilers include between the front-end phases and code generation can be broadly split in two categories:
- simplification phases
- which translate complex concepts of the language (e.g. pattern matching, anonymous functions) into simpler ones, and
- optimization phases
- which try to improve the program's usage of some resource (e.g. CPU time, memory, energy).
To manipulate the program, these phases must represent it in some way. One possibility is to use the representation produced by the parser — the abstract syntax tree (AST). While this is perfectly suited to certain tasks, other intermediate representations (IR) exist and are more appropriate in some situations.
The choice of the intermediate representation to use in a compiler is of paramount importance, as it greatly influences the difficulty of performing certain analyses or transformations. For that reason, many intermediate representations have been developed, and most compilers use more than one of them at different stages of the compilation process.
3.1 Simplification phases
A simplification (also called lowering) phase is one that transforms the program being compiled so that some complex concept of the input language is translated using simpler ones.
As an example, all Java compilers include a phase that transforms nested classes to top-level ones. This phase is necessary as the Java Virtual Machine does not have a notion of nested class. The effect of this simplification phase on a simple program is illustrated in the image below:

3.2 Optimization phases
An optimization phase is one that transforms the program being compiled so that it (hopefully) makes better use of some resource: CPU cycles, memory, energy, etc.
An example of an optimization phase found in most Java compilers is the one that removes if statements whose condition is known at compilation time to be false. This kind of code is commonly referred to as dead code, i.e. code that can never be executed.
The effect of this optimization phase on a simple program is illustrated in the image below:

Unlike simplification phases, which are mandatory, optimization phases are not and can often be enabled or disabled by the user of the compiler. There are exceptions, though, and some programming language specifications require that conforming compilers always perform a defined set of optimizations.
4 Run time systems
Implementing a high-level programming language usually means more than just writing a compiler. A complete run time system must be written, to provide various services to executing programs, like:
- code loading and linking,
- code interpretation, compilation and optimization,
- memory management (garbage collection),
- concurrency,
- etc.
This is quite a lot, and typical implementations of run time systems for Java (called Java Virtual Machines) are more complex than Java compilers!
4.1 Memory management
Most modern programming languages offer automatic memory management: the programmer allocates memory explicitly, but deallocation is performed automatically.
The deallocation of memory is usually performed by a part of the run time system called the garbage collector, which periodically frees all memory that has been allocated by the program but is not reachable anymore.
4.2 Virtual machines
Instead of targeting a real processor, a compiler can target a virtual one, usually called a virtual machine (VM). The produced code is then interpreted by a program emulating the virtual machine.
Virtual machines have many advantages:
- the compiler can target a single architecture,
- the program can easily be monitored during execution, e.g. to prevent malicious behavior, or provide debugging facilities,
- the distribution of compiled code is easier.
The main (only?) disadvantage of virtual machines is their speed: it is always slower to interpret a program in software than to execute it directly in hardware.
To make virtual machines faster, dynamic, or just-in-time (JIT) compilation was invented. The idea is simple: Instead of interpreting a piece of code, the virtual machine translates it to machine code, and hands that code to the processor for execution. This is usually faster than interpretation.